本篇介绍tensor的维度变化。
维度变化改变的是数据的理解方式!
- view/reshape:大小不变的条件下,转变shape
- squeeze/unsqueeze:减少/增加维度
- transpose/t/permute:转置,单次/多次交换
- expand/repeat:维度扩展
view reshape
- 在pytorch0.3的时候,默认是view .为了与numpy一致0.4以后增加了reshape。
- 损失维度信息,如果不额外存储/记忆的话,恢复时会出现问题。
- 执行view/reshape是有一定的物理意义的,不然不会这样做。
- 保证tensor的size不变即可/numel()一致/元素个数不变。
- 数据的存储/维度顺序非常非常非常重要
1 | In[4]: a = torch.rand(4,1,28,28) |
squeeze 与 unsqueeze
unsqueeze
- unsqueeze(index) 拉伸(增加一个维度) (增加一个组别)
- 参数的范围是 [-a.dim()-1, a.dim()+1) 如下面例子中范围是[-5,5)
- -5 –> 0 … -1 –> 4 这样的话,0表示在前面插入,-1表示在后面插入,正负会有些混乱,所以推荐用正数。
- 0与正数,就是在xxx前面插入。
1 | In[17]: a.shape |
实际案例
给一个bias(偏置),bias相当于给每个channel上的所有像素增加一个偏置
为了做到 f+b 我们需要改变b的维度
1 | In[28]: b = torch.rand(32) |
后面进一步扩张到 [4,32,14,14]
queeze
- squeeze(index) 当index对应的dim为1,就产生作用。
- 不写参数,会挤压所有维度为1的。
1 | In[38]: b.shape |
expand / repeat
- Expand:broadcasting (推荐)
- 只是改变了理解方式,并没有增加数据
- 在需要的时候复制数据
- Reapeat:memory copied
- 会实实在在的增加数据
上面提到的b [1, 32, 1, 1] f[ 4, 32, 14, 14 ]
目标是将b的维度变成与f相同的维度。
expand
- 扩展(expand)张量不会分配新的内存,只是在存在的张量上创建一个新的视图(view)
1 | In[44]: a = torch.rand(4,32,14,14) |
repeat
- 主动复制原来的。
- 参数表示的是要拷贝的次数/是原来维度的倍数
- 沿着特定的维度重复这个张量,和expand()不同的是,这个函数拷贝张量的数据。
1 | In[49]: b.shape |
转置
.t
转置操作
- .t 只针对 2维矩阵
1 | a = torch.randn(3,4) |
transpose
- 在结合view使用的时候,view会导致维度顺序关系变模糊,所以需要人为跟踪。
- 错误的顺序,会导致数据污染
- 一次只能两两交换
- contiguous
1 | # 由于交换了1,3维度,就会变得不连续,所以需要用contiguous,来吧数据变得连续。 |
permute
- 会打乱内存顺序,待补充!!!
- 由于transpose一次只能两两交换,所以变换后在变回去至少需要两次操作,而permute一次就好。例如对于[b,h,w,c]
- [b,h,w,c]是numpy存储图片的格式,需要这一步才能导出numpy
1 | In[18]: a = torch.rand(4,3,28,28) |
Broadcast
自动扩展:
- 维度扩展,自动调用expand
- without copying data ,不需要拷贝数据。
核心思想
- 在前面插入1维
- 将size 1 扩展成相同 size 的维度
例子:
- 对于 feature maps : [4, 32, 14, 14],想给它添加一个偏置Bias
- Bias:[32] –> [32, 1 , 1] (这里是手动的) => [1, 32, 1, 1] => [4, 32, 14, 14]
- 目标:当Bias和feature maps的size一样时,才能执行叠加操作!!!
Why broadcasting?
就像下图表示的一样:我们希望进行如下的几种计算,但需要满足数学上的约束(size相同),为了节省人们为满足数学上的约束而手动复制的过程,而产生的Broadcast,它节省了大量的内容消耗。
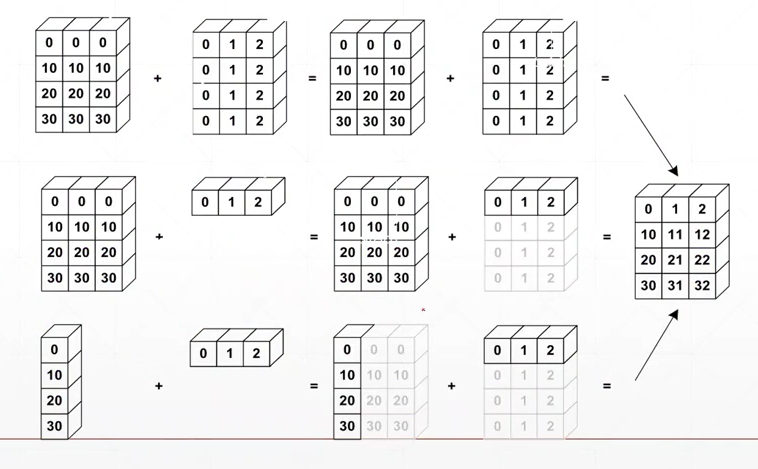
- 第二行数据中 [3] => [1, 3] => [4, 3] (行复制了4次)
- 第三行数据中
- [4,1] => [4, 3] (列复制了3次)
- [1,3] => [4, 3] (行复制了4次)
- broadcast = unsqueze(插入新维度) + expand(将1dim变成相同维度)
例子:
- 有这样的数据 [class, students, scores],具体是4个班,每个班32人,每人8门课程[4, 32, 8] 。
- 考试不理想,对于这组数据我们需要为每一位同学的成绩加5分
- 要求: [4, 32, 8] + [4, 32, 8]
- 实际上:[4, 32, 8] + [5.0]
- 操作上:[1] =>(unsqueeze) [1, 1, 1] =>(expand_as) [4, 32, 8],这样需要写3个接口。
- 所以才会有 broadcast!!
内存分析:
- [4, 32, 8] => 1024
- [5.0] => 1 如果是手动复制的话,内存消耗将变为原来的1024倍
使用条件?
A [ 大维度 —> 小维度 ]
从最后一位(最小维度)开始匹配,如果维度上的size是0,1或相同,则满足条件,看下一个维度,直到都满足条件为止。
- 如果当前维度是1,扩张到相同维度
- 如果没有维度,插入一个维度并扩张到相同维度
- 当最小维度不匹配的时候是没法使用broadcastiong,如共有8门课程,但只给了4门课程的变化,这样就会产生歧义。
note:小维度指定,大维度随意
小维度指定:假如英语考难了,只加英语成绩 [0 0 5 0 0 0 0 0]
案例
情况一
A[4, 32, 14, 14]
B[1, 32, 1, 1] => [4,,32, 14, 14]
情况二
A[4, 32, 14, 14]
B[14, 14] => [1, 1, 14, 14] => [4, 32, 14, 14]
情况三
不符合条件
A[4, 32, 14, 14]
B[2, 32, 14, 14]
理解这种行为
- 小维度指定,大维度随意。小维度设定规则(加5分),大维度默认按照这个规则(通用)。
- 维度为1才满足条件,是为了保证公平(统一的规则)
常见使用情景
- A [4, 3, 32, 32] b,c,h,w
- +[32, 32] 叠加一个相同的feature map,做一些平移变换。相当于一个base(基底),
- +[3, 1, 1] 针对 RGB 进行不同的补充,如R 0.5 、G 0 、B 0.3
- +[1, 1, 1, 1] 对于所有的都加一个数值,抬高一下,如加0.5.

