本篇是在学习进程]和线程的基础知识和相关模块后对并发编程的继续深入学习。首先是对
Cpython的GIL进行介绍,GIL为什么会被质疑以及对GIL的正确认识。
GIL(Global Interpreter lock)
GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。由于CPython是大部分环境下默认的Python执行环境,很多人就把CPython同Python画上等号,也就像当然把GIL归结为Python语言的缺陷。下面是官方文档的解释:
The mechanism used by the CPython interpreter to assure that only one thread executes Python bytecode at a time. This simplifies the CPython implementation by making the object model (including critical built-in
types such as dict) implicitly safe against concurrent access. Locking the entire interpreter makes it easier for the interpreter to be multi-threaded, at the expense of much of the parallelism afforded by multi-processor machines.
GIL机制使Cpython解释器一次只执行一条线程,这种设计简化了CPython的实现,使得对象模型,包括关键的内建类型如字典,都是隐含可以并发访问的。锁住全局解释器使得比较容易的实现对多线程的支持,但也损失了多处理器主机的并行计算能力。
简单的一句话就是GIL是一种阻止同时有多个线程执行Python字节码的互斥机制,对于一个进程下的多线程,我们只能做到并发,无法达到并行。
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
可能大家看到这里会有一丝疑惑,怎么一会儿说是并发,一会儿说是串行。这是因为多个线程的代码,轮流被解释器执行(执行的是拿到GIL的那个线程),只不过切换的频率很高,给人一种多个进程在“同时”执行的错觉,所以多线程可以做到并发,串行是体现在只有一个线程能拿到GIL锁。
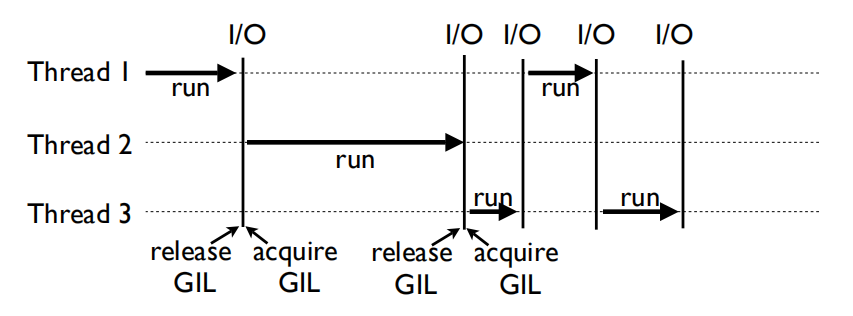
结合上图,在多线程环境中,Python虚拟机按照以下方式执行:
- 设置GIL
- 切换到一个线程去执行
- 运行
- 把线程设置为睡眠状态
- 解锁GIL
- 再次重复以上步骤
GIL的历史
Python出现的时候还是单核CPU的时代。Python代码的执行依赖于解释器,由Python 虚拟机(也叫解释器主循环,CPython版本)来控制,Python 在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即在任意时刻,只有一个线程在解释器中运行。对Python 虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。在那个单核时代,这种设计方式使得单线程更快,并且在和C库结合时更方便,不用考虑线程安全问题。
随着双核CPU的问世,人们就会意识到线程实际上可以在同一时间运行。真正的并行性,而不仅仅是并发性。虽然线程不是为了这个目的,但它们很好地发挥了作用,甚至不需要引入新的概念。但是对于Python,此时由于内置库和第三方库已经对GIL形成了牢不可破的依赖,想改革GIL反而变得困难了。有些项目试图在没有GIL的情况下实现Python项目,甚至有些人直接从CPython中删除了GIL,但效果很不理想。
Python的解析器 :
- 含有GIL的有:CPython、PyPy、Psyco;
- 没有GIL的有:Jython,IronPython。
验证Cpython的并发效率
I/O密集型任务
开启150个进程,执行I/O任务,计算耗时:
1 | # 多进程 |
1 | 结果是: |
开启150个线程,执行I/O任务,计算耗时:
1 | # 多线程 |
1 | 结果是: |
结论:
任务是I/O密集型并且任务数量很大,用单进程下的多线程效率很高。
计算密集型任务
开启10个进程,并计算耗时:
1 | from multiprocessing import Process |
1 | 结果: |
开启10个线程,并计算耗时:
1 | from threading import Thread |
1 | 结果: |
GIL与互斥锁的关系
GIL自动上锁,解锁;文件中的互斥锁Lock是手动上锁,解锁。
GIL锁保护解释器的数据安全;文件中的互斥锁Lock保护文件的数据安全。
GIL锁保证了进程安全;Lock锁保证了线程安全。
GIL要保证同一时刻只有一个线程在解释器中运行,进而保证了进程安全
进程是系统资源分配的最小单位,线程是程序执行的最小单位。多线程环境中,共享数据同一时间只能有一个线程来操作,不然中间过程可能会产生不可预制的结果,所以这就保证了线程安全
当前GIL设计的缺陷
以下图片来自[Understanding the Python GIL][https://speakerdeck.com/dabeaz/understanding-the-python-gil],还有[Youtube视频解释][https://www.youtube.com/watch?v=Obt-vMVdM8s]。
对于单核CPU下的多线程
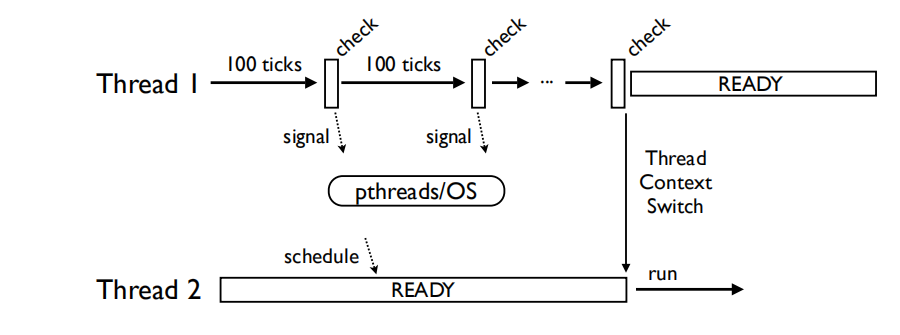
- 线程交替执行,但切换频率远低于你的想象,在线程上下文切换之前可能会发生数百上千次检查。
- 这是没有问题,也是表现很好的。但问题随着多核的出现而出现。
对于多核CPU下的多线程:
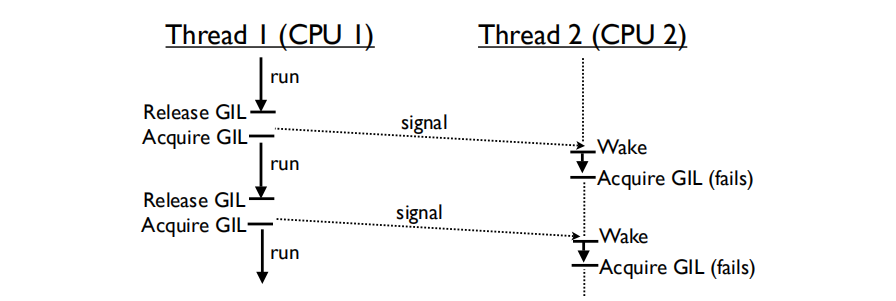
使用多个cpu,可运行的线程可以同时(在不同的cpu上)进行调度,并通过GIL进行争夺。
线程2不断地接受信号,可当它醒来时GIL已经被其他线程取走了。
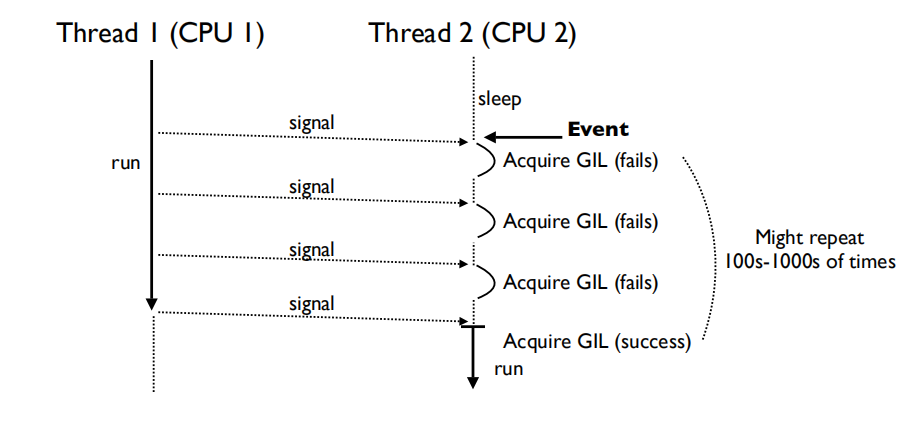
- 对于计算密集型任务来说,想要处理事件的其他线程很难获取GIL。
虽然在Python3.2出现了一个新的GIL,对上面的这种不公平现象进行了一定的解决(convoy effect(FCFS算法),但也出现了其它方面的下降。
替代方案
计算密集型任务交给multiprocess(多进程)
multiprocess库的出现很大程度上是为了弥补thread库因为GIL而低效的缺陷。它完整的复制了一套thread所提供的接口方便迁移。唯一的不同就是它使用了多进程而不是多线程。每个进程有自己的独立的GIL,因此也不会出现进程之间的GIL争抢。但它也存在着开辟耗费的资源高,进程间的通信复杂,我们要做好平衡。
用其他解释器(不推荐)
之前也提到既然GIL只是CPython的产物,那么其他解析器是不是更好呢?没错,像Jython和IronPython这样的解析器由于实现语言的特性,他们不需要GIL的帮助。然而由于用了Java/C#用于解析器实现,他们也失去了利用社区众多C语言模块有用特性的机会。所以这些解析器也因此一直都比较小众。毕竟功能和性能大家在初期都会选择前者,Done is better than perfect。
通过C扩展实现(难度高)
只需要把关键部分用 C/C++ 写成 Python 扩展,其它部分还是用 Python 来写,让 Python 的归Python,C 的归 C。一般计算密集性的程序都会用 C 代码编写并通过扩展的方式集成到 Python 脚本里(如 NumPy 模块)。在扩展里就完全可以用 C 创建原生线程,而且不用锁 GIL,充分利用 CPU 的计算资源了。
[推荐阅读][https://blog.csdn.net/nbadwde/article/details/80713819]
总结
GIL是一把大锁,它带来了方便和安全,但也留下了遗憾(无法并行)。
Python GIL其实是功能和性能之间权衡后的产物,它尤其存在的合理性,也有较难改变的客观因素。
我们要根据任务性质来决定使用多线程还是多进程,还是通过C扩展来完成计算密集型。

